

هل سبق أن سمعت عن علم البيانات (Data Science)؟ إن لم تكن سمعت عن هذا العلم من قبل فيكفي القول بأنّ وظيفة عالِم البيانات (Data Scientist) أصبحت من أكثر الوظائف طلبًا في القرن الحادي والعشرين، وأنّ علم البيانات أصبح من الكلمات الرّنّانة الّتي يتحدّث بها كل المشتغلين بمجالات التّكنولوجيا في عصرنا الحاليّ. تعالوا في هذا المقال لنتعرّف أكثر إلى علم البيانات، وإلى الدّور الّذي يقوم به عالِم البيانات، وعلى الأدوات اللّازمة لاحتراف هذا العلم المُمتع.
تعريف علم البيانات
يعتبر علم البيانات أحد فروع علوم الحاسب، وهو يتعامل مع استخلاص ومعالجة وتحليل البيانات لاكتساب رؤًى جديدةٍ أو للإجابة عن أسئلةٍ مُعيّنةٍ حول هذه البيانات.
يتعامل عالم البيانات مع كمّياتٍ ضخمةٍ من المعلومات من مختلف المصادر وبمختلف الأشكال؛ لذا فإنّ عمليّة المعالجة الّتي يقوم بها علماء البيانات عادةً ما تكون فريدةً من نوعها لكلّ دراسةٍ، وتستخدم خوارزميّاتٍ مخصّصةٍ، ومهارات الذّكاء الاصطناعيّ (Artificial Intelligence)، وتعلّم الآلة (Machine Learning)، وغيرها.
بناءً على ما سبق، يمكن القول بأنّ علم البيانات هو علمٌ متعدّد التّخصّصات؛ يجمع بين الرياضيّات والإحصاء وعلوم الحاسب للتّعامل مع البيانات بصورةٍ أكثر كفاءةً. يعتبر علم البيانات من العلوم واسعة الانتشار، فهو يُستخدَم في الوقت الحاليّ في كثيرٍ من المجالات والصّناعات مثل: الطّبّ، والفلك، والأرصاد الجويّة، والتّسويق، والعلوم الاجتماعيّة، وغيرها الكثير. [1][2]
أهمية علم البيانات
تكمن أهمّيّة علم البيانات في دخوله في جميع الصّناعات تقريبًا، فهو بمثابة وقودٍ للصّناعات، أو كهرباء جديدةٍ لا قيام للصّناعات بدونها. يساعد النّهج القائم على البيانات (Data Driven Approach) علماء البيانات في الشّركات في تحليل كمّياتٍ كبيرةٍ من البيانات؛ لاستخراج رؤًى مختلفةٍ وذات معانٍ مختلفةٍ. هذه الرّؤى لها قيمةٌ كبيرةٌ في مساعدة الشّركات لتقييم أدائها في سوق العمل. لا يختصّ تطبيق علم البيانات على الصّناعات التّجاريّة فقط، بل إنّ قطاع الرّعاية الصحيّة يستخدم علم البيانات أيضًا؛ حيث يساعد تطبيق هذه التّكنولوجيا في التّعرُّف على الأورام الميكروسكوبيّة والتّشوّهات في مرحلةٍ مبكّرةٍ من التّشخيص.[2]
ازدادت أعداد وظائف علماء البيانات بنسبة 650% بين عامي 2012 و2019م، وطبقًا لإحصائيّات مكتب العمل الأمريكيّ (U.S. Bureau of Labor) سيكون هناك ما يقرب من 11.5 مليون وظيفة عالم بياناتٍ قبل عام 2026م. كذلك، تُصنّف وظيفة عالم البيانات بين أعلى الوظائف النّاشئة على موقع لينكد-إن (LinkedIn)، وكلّ الإحصائيّات تتّجه نحو زيادة الطّلب على وظيفة عالم البيانات في المستقبل.[2]
وظيفة عالِم البيانات
عالم البيانات: أكثر الوظائف إثارةً في القرن الحادي والعشرين
مجلّة «هارفَرد بِزنِس ريفيو»[3]
تعال لنعرف في الأسطر القادمة من هو عالِم البيانات، وما هو الدّور الّذي يقوم به في مختلف المجالات.
يتعامل عالِم البيانات مع نوعين من البيانات: البيانات المنظّمة (Structured Data)، والبيانات غير المنظّمة (Unstructured Data). توجد البيانات غير المنظّمة في صورتها الخام، فتحتاج إلى معالجةٍ شاملةٍ قبل الاستخدام، تتضمّن التّصفية والتّنظيم؛ من أجل تحويلها إلى صورةٍ منظّمةٍ يسهل التّعامل معها. يقوم عالِم البيانات بعدها باستكشاف هذه البيانات المرتّبة، وتحليلها بصورةٍ عميقةٍ لاستخراج المعلومات المطلوبة باستخدام العديد من الطّرق الإحصائيّة. باستخدام هذه الطّرق الإحصائيّة يقوم عالِم البيانات بوصف وتمثيل هذه البيانات في صورة رسوماتٍ بيانيّةٍ، وافتراض معلوماتٍ معيّنةٍ من هذه البيانات. بهذا مع استخدام أدواتٍ متقدّمةٍ من خوارزميّات تعلّم الآلة يمكن لعالِم البيانات التّنبّؤ بوقوع أحداثٍ معينةٍ، واتّخاذ قراراتٍ مبنيّةٍ على هذه البيانات.[2]
يستخدم عالِم البيانات العديد من الأدوات والممارسات للتّعرّف على الأنماط المختلفة الّتي تحتويها البيانات. تتنوّع هذه الأدوات بين استخدام لغات البرمجة مثل: لغة الاستعلامات البنائيّة (Structured Query Language)، ولغة البايثون (Python)، ولغة آر (R)، وأدوات التّعامل مع البيانات الضّخمة مثل: هادوب (بالإنجليزيّة: Hadoop)، وأدوات عمل نماذج تعلّم الآلة والتّنقيب عن البيانات مثل: ويكا (Weka)، وأدوات تمثيل ورسم البيانات مثل: برنامج تابلو (Tableau).
يُعتبر عالِم البيانات ككيانٍ استشاريٍّ، تُوظّفه الشّركات للمشاركة في عمليات صنع القرار، وعمل الخطط الاستراتيجيّة، عن طريق الرّؤى الّتي يستخلصها من البيانات المختلفة. على سبيل المثال، تستخدم شركاتٌ مثل: نِتفلِكس (بالإنجليزيّة: Netflix)، وجوجل (بالإنجليزيّة: Google)، وأمازون (Amazon)، علم البيانات لتطوير أنظمة توصياتٍ مختلفةٍ للمستخدمين، وبنفس الكيفيّة تستخدم العديد من الشّركات الماليّة، التّحليلات التّنبّؤيّة وأنظمة التّوقّع؛ للتّنبّؤ بتغيّر الأسعار في أسواق البورصة. ولنختصر الأمر؛ قد ساعد علم البيانات على خلق أنظمةٍ أكثر ذكاءً، بإمكانها اتّخاذ قراراتٍ مستقلّةٍ، اعتمادًا على البيانات التّاريخيّة السّابق معرفتها. وبسبب تداخل علم البيانات مع تكنولوجياتٍ حديثةٍ ناشئةٍ مثل: الرّؤية الحاسوبيّة (Computer Vision)، ومعالجة اللّغات الطّبيعيّة (Natural Language Processing)، والتّعليم المعزّز (Reinforcement Learning)، أظهر علم البيانات نفسه على السّاحة الحديثة كإحدى الصّور العظيمة للذّكاء الاصطناعيّ.[2]
خطوات التعامل مع البيانات
تتكوّن عمليات التعامل مع البيانات من ستّ خطواتٍ رئيسيّةٍ، لا بدّ لعالم البيانات من المرور بها أثناء حلِّه لمعظم مشاكل الحياة الواقعيّة، وهي كالتّالي:[4]
تحديد الهدف من البحث
يُطبَّق علم البيانات غالبًا في المشاريع المتعلّقة بالمنظّمات، حيث يقوم مسؤولو المنظّمة بإعداد وثيقةٍ متعلقةٍ بكلّ مشروعٍ؛ تُوضِّح هدف المشروع. تحتوي هذه الوثيقة على معلوماتٍ مثل: ما هو نطاق تطبيق البحث، وكيف ستستفيد المنظّمة من هذا البحث، وما هي البيانات والمصادر المطلوبة لعمليّة البحث، إضافةً إلى الإطار الزمنيّ والعناصر المطلوب تسليمها في نهاية هذا البحث.
جمع البيانات
تعتبر عمليّة جمع البيانات هي المرحلة الثّانية بعد معرفة الغرض من البحث، والبيانات الّتي نحتاجها ومكان تواجدها عن طريق إعداد وثيقة المشروع. في هذه الخطوة يقوم عالم البيانات بالتّأكُّد من توفُّر هذه البيانات، من خلال معرفة إمكانيّة الوصول إليها، وفحص جودتها -إن وُجدت-. يمكن أيضًا الحصول على هذه البيانات من مصدرٍ خارج المنظّمة، ويمكن أن تأخذ هذه البيانات العديد من الصّور، كجداول إكسلّ، أو قوائم بياناتٍ بمختلف أنواعها.
إعداد البيانات
في هذه المرحلة يقوم عالم البيانات بتجهيز البيانات الّتي قد جُمِعت في الخطوة السّابقة، وزيادة جودتها، وإعدادها للاستخدام في المراحل التّالية. تتكوّن عمليّة إعداد البيانات من ثلاث مراحل ثانويّةٍ، كالآتي:
- تطهير البيانات: عن طريق إزالة السّجلّات الخاطئة والبيانات المتناقضة.
- تكامل البيانات: عن طريق تجميع البيانات من أكثر من مصدرٍ؛ ممّا يحسّن من جودة البيانات.
- تحويل البيانات: إلى صورةٍ مناسبةٍ يمكن التّعامل معها واستخدامها في عمل النّماذج.
استكشاف البيانات
تقوم عمليّة استكشاف البيانات على بناء فهمٍ أعمق للبيانات، ومحاولة فهم الرّوابط بين المتغيّرات، وأنماط توزيع البيانات، ومعرفة إذا كانت هناك قيمٌ شاذّةٌ للمتغيّرات أم لا. لتحقيق ما سبق، تُستخدم الإحصاء الوصفيّة، وطرق التّمثيل البيانيّ، وعمل النّماذج البسيطة، وفي الغالب تٌسمّى هذه العمليّة بالتّحليل الاستكشافيّ للبيانات (Exploratory Data Analysis).
نمذجة البيانات أو بناء النماذج
في هذه المرحلة، يبدأ عالم البيانات باستخدام نماذج البيانات (بالإنجليزيّة: Data Models)، والمعرفة بمجال التّطبيق، والرّؤى المكتسبة من البيانات عبر الخطوات السّابقة؛ من أجل الإجابة على سؤال البحث. لعمل هذه النّماذج؛ تُستخدم طرقٌ مختلفةٌ من علم الإحصاء، وتعلّم الآلة، وبحوث العمليّات أو علم اتّخاذ القرار (Operations Research)، إلخ. وتعتبر عمليّة بناء النّماذج عمليّةً تكراريّةً، تتضمّن: تحديد متغيّرات النّموذج، وتنفيذ النّموذج، وفحص النّموذج بعد الانتهاء.
عرض المخرجات
تعتبر آخر مراحل التّعامل مع البيانات هي مرحلة عرض المخرجات على أصحاب المشاريع. يمكن للمخرجات أن تتّخذ أكثر من صورةٍ، من عروضٍ توضيحيّةٍ، وحتّى تقديم التّقارير البحثيّة. وفي بعض الأحيان، يقوم عالم البيانات بتحويل المخرجات إلى صورةٍ أوتوماتيكيّةٍ (Automation)؛ حتّى تفيد أصحاب الأعمال في استخدام الرّؤى المكتسبة من المشاريع الحاليّة في مشاريع أخرى، أو استخدام هذه المخرجات في العمليّة التّشغيليّة.
حل المشكلات باستخدام علم البيانات
يقوم عالِم البيانات بتحليل البيانات من خلال العديد من الطّرق الإحصائيّة، وعلى وجه الخصوص، يستخدم عالم البيانات إحدى هاتين الطّريقتين:[2]
- الإحصاء الوصفيّة (Descriptive Statistics).
- الإحصاء الاستدلاليّة (Inferential Statistics).
افترض أنّك أحد علماء البيانات العاملين بإحدى شركات تصنيع الهواتف المحمولة. الآن مطلوبٌ منك أن تقوم بتحليل العملاء الّذين يستخدمون الهواتف المحمولة الّتي تقوم شركتك بتصنيعها. لكي تتمكّن من فعل ذلك، يجب عليك أوّلًا أن تأخذ نظرةً عميقةً حول بيانات هؤلاء العملاء، وتحاول فهم التّوجّهات المختلفة والأنماط الّتي تحتوي عليها تلك البيانات. وفي النّهاية، ستقوم بتلخيص هذه البيانات، واستخراجها في صورة أشكالٍ ورسوماتٍ بيانيّةٍ، توضّح هذه الأنماط، وتقارن بين العوامل المختلفة لهؤلاء العملاء. هنا يمكن القول بأنّك قد طبقّت الإحصاء الوصفيّة لحلّ هذه المشكلة.[2]
ماذا لو أردت تطبيق الإحصاء الاستدلاليّة لاستخراج استنتاجاتٍ حول هذه البيانات. كمثالٍ على تطبيق الإحصاء الاستدلاليّة في تحليل البيانات، لنفترض ثانيةً أنّك ترغب في إيجاد عدد عيوب الهواتف المحمولة الّتي قد توجد في كميّاتٍ كبيرةٍ من الإنتاج. إنّ عمليّة الاختبار الفرديّة لكلّ جهازٍ قد تكون عمليّةً غايةً في الصّعوبة، وقد تستهلك كثيرًا من الوقت والمصاريف. لذلك كلّ ما علينا هو أخذ عيّنة من هذه الهواتف، وعمل اختباراتٍ لها لإيجاد نسبة العيوب الموجودة بها، ومن ثم عمل تعميمٍ (Generalization) باستخدام الإحصاء لتقدير نسبة العيوب في الكمّيّة الإجماليّة.[2]
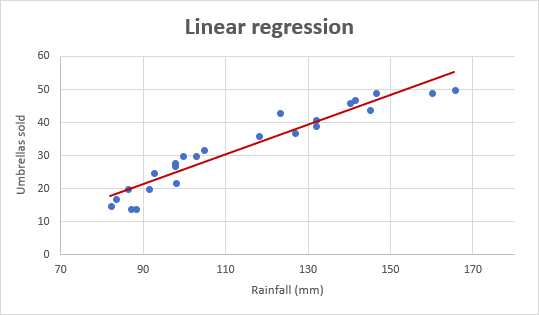
لنقل أنّنا نريد أن نتنبّأ بمبيعات الهواتف المحمولة خلال فترةٍ من الزّمن: عامين مثلًا. يمكن هنا استخدام خوارزميّةٍ تقوم بعمل ما يُسمّى في علم الإحصاء بتحليل الانحدار (Regression Analysis)، فبناءً على البيانات السّابقة للمبيعات، يمكن لتحليل الانحدار هذا التّنبّؤ بالمبيعات القادمة خلال عامين.[2]
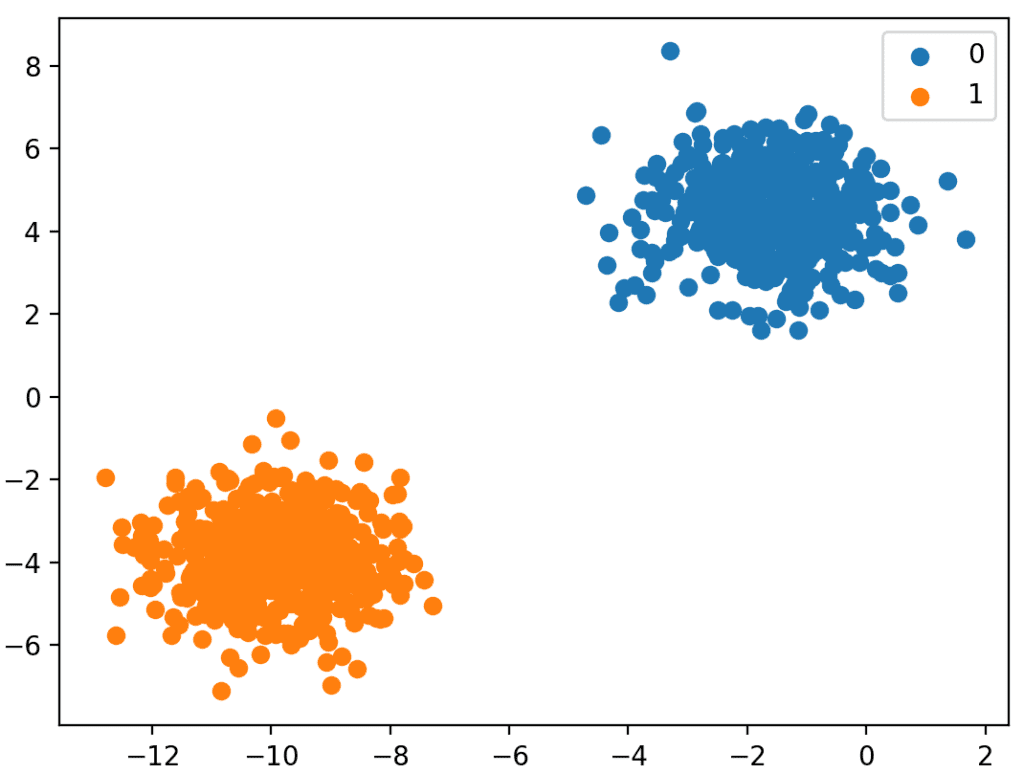
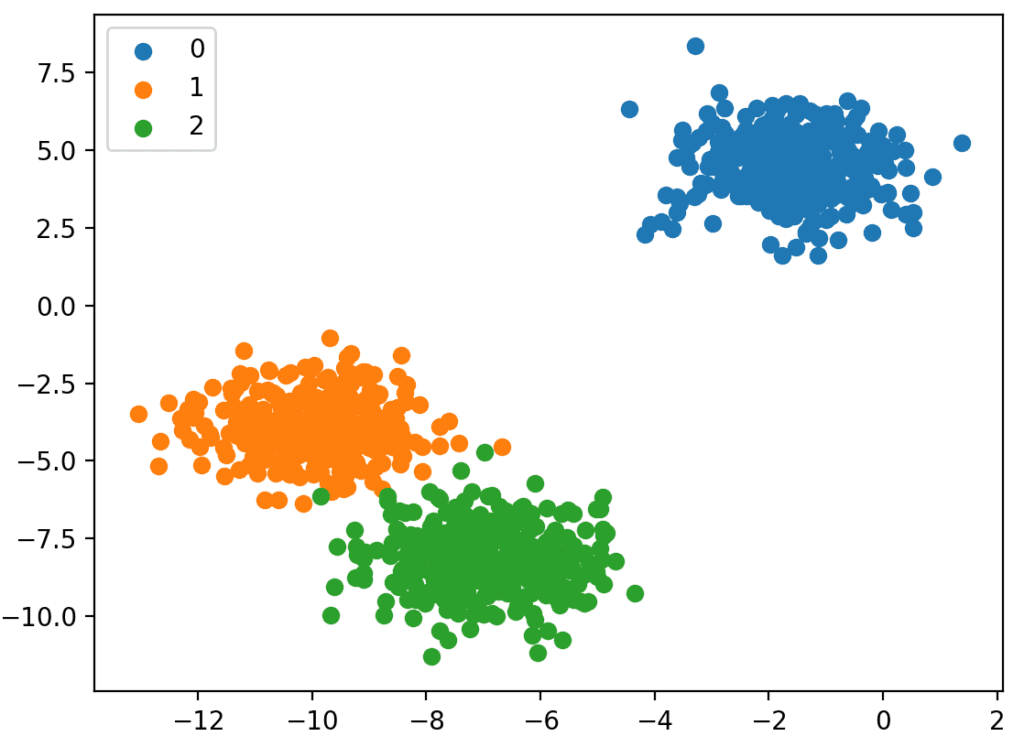
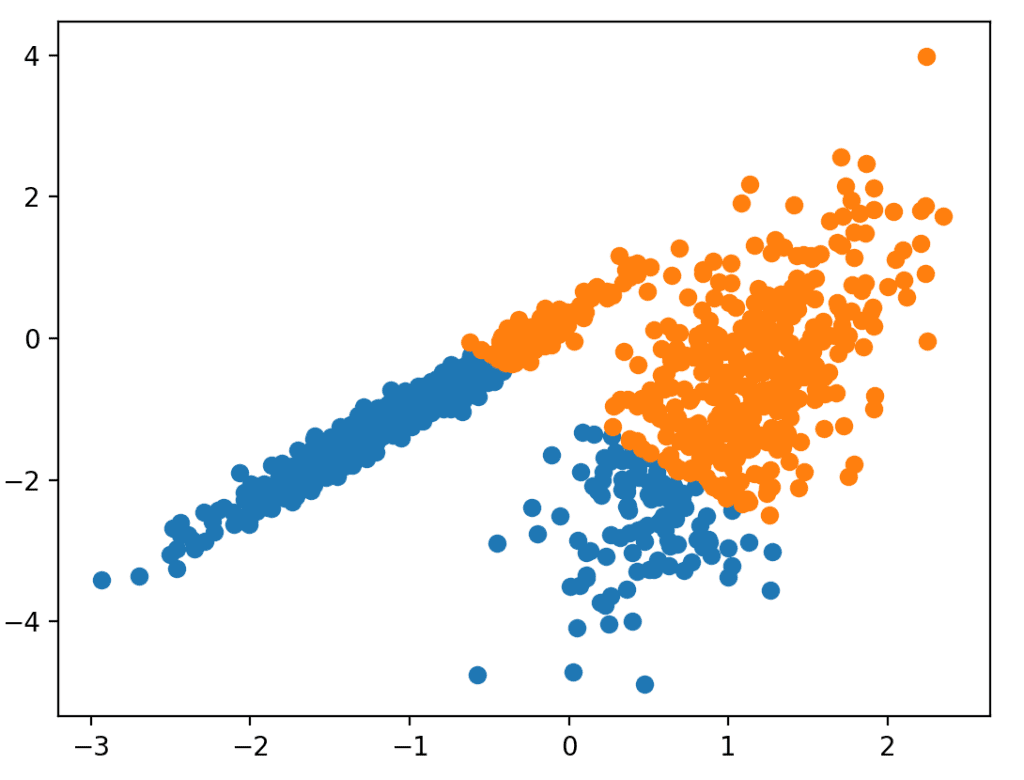
صورة [3]: التّصنيف الثنائيّ، والتّصنيف متعدّد المتغيّرات
في بعض الأحيان أيضًا يمكن التّعامل مع نوعٍ من البيانات غير المصنّفة (Unlabeled Data)، حيث لا يوجد تقسيمٌ للخصائص أو المخرجات في تصنيفاتٍ ثابتةٍ مثل المثال السّابق. لتوضيح الأمر، لنفترض أنّك تريد معرفة العملاء المحتملين بين مجموعةٍ من النّاس اعتمادًا على خلفيّاتهم الاجتماعيّة والاقتصاديّة. في هذا المثال لا توجد تصنيفاتٌ ثابتةٌ للبيانات التّاريخيّة الّتي نمتلكها، لذا يجب استخدام خوارزميّةٍ تصنيفيّةٍ (Clustering Algorithm)؛ لعمل تصنيفاتٍ لمجموعة البيانات لمعرفة العملاء المحتملين. هذا النّهج يسمّى بالتّعلّم غير المُراقَب أو التّعلّم الاستنتاجيّ (Unsupervised Learning)، وهو أيضًا أحد تعلّم الآلة.[2]

الأدوات التي يحتاجها عالم البيانات
يستخدم علماء البيانات طرق الإحصاء التّقليديّة، والّتي تشكّل العمود الفقري لخوارزميّات تعلّم الآلة. كذلك، يستخدم علماء البيانات خوارزميّات التّعلّم العميق (Deep Learning) لعمل تنبّؤاتٍ دقيقةٍ اعتمادًا على البيانات المتوفّرة. من أجل تنفيذ هذه الأمور يستخدم عالم البيانات عددًا من الأدوات ولغات البرمجة الّتي يؤدّي بها الغرض المطلوب، نذكر بعضًا منها كالآتي:[2]
لغة آر (R)
تعتبر لغة آر لغةً برمجيّةً نصّيّةً، أُنشئت للتّعامل مع مشكلات الحوسبة الإحصائيّة. تُستخدم هذه اللّغة بكثرةٍ في تحليل البيانات، وعمل النّماذج الإحصائيّة، والتّنبّؤ المبنيّ على السّلاسل الزّمنيّة، وعمليّات التّصنيف (Clustering)، إلخ. تمتلك لغة آر أيضًا مميّزات البرمجة شيئيّة التّوجّه (Object Oriented Programming) والّتي تعتبر إحدى أنماط البرمجة المتقدّمة. تعتبر لغة آر من أكثر اللّغات انتشارًا في عمليّات التّحليل الإحصائيّ في العديد من الشّركات.
لغة بايثون (Python)
مثل لغة آر، تعتبر لغة بايثون من لغات البرمجة عالية المستوى، وهي تُستخدم في العديد من الأغراض، وتُستخدم بكثرةٍ في علم البيانات، وفي تطوير البرمجيّات. اكتسبت لغة بايثون شعبيّتها بسبب سهولة استخدامها، وسهولة قراءة الكود الّذي تُكتب به. بسبب ذلك، تستخدم لغة بايثون بكثرةٍ في عمليّات تحليل البيانات، ومعالجة اللّغات الطبيعيّة (NLP)، والرّؤية الحاسوبيّة. تحتوي لغة بايثون على العديد من المكتبات الّتي تُستخدم في التّحليل الإحصائيّ مثل: نَمباي (NumPy)، وسايباي (SciPy)، والمكتبات الّتي تُستخدم في الرّسم البيانيّ مثل: مات بلوت ليب (Matplotlib)، ومكتباتٍ أخرى أكثر تقدمًا مثل تلك الّتي تستخدم في التّعلّم العميق وتعلّم الآلة مثل: تِنسُر فلو (TensorFlow)، وباي تورش (PyTorch)، وكيراس (Keras). لذا يمكن القول بأنّ لغة بايثون يمكن استخدامها لأغراض التّنقيب عن البيانات (Data Mining)، وتحويل البيانات من صورةٍ لأخرى (Data Wrangling)، وإنشاء الرّسومات البيانيّة، وعمل النّماذج التّنبّؤيّة؛ ممّا يجعل لغة بايثون أحد أكثر لغات البرمجة مرونةً.

لغة إس كيو إل (SQL)
ترمز الحروف (SQL) إلى لغة الاستعلامات البنائيّة (Structured Query Language)، والّتي تُستخدم لإدارة البيانات المُخزّنة في قواعد البيانات، والاستعلام عنها. تعتبر عمليّة استخراج البيانات من قواعد البيانات هي أولى الخطوات الّتي تمكّننا من تحليل البيانات. تتعامل لغة إس كيو إل أيضًا مع قواعد البيانات المترابطة (بالإنجليزيّة: Relational Databases)، وهي مجموعةٌ من الجداول المُنظّمة، ويمكن الرّبط بينها بمفاتيح مشتركةٍ. يمكن استخدام لغة إس كيو إل لاستخراج وإدارة وتعديل البيانات الموجودة في هذا النّوع من قواعد البيانات.
برنامج هادوب (Hadoop)
أحد المصطلحات المنتشرة اليوم أيضًا في علم البيانات هو مصطلح البيانات الضّخمة (Big Data)، والّذي يتعامل مع إدارة وتخزين كمّيّاتٍ ضخمةٍ من البيانات سواءً كانت منظّمةً أو غير منظّمةٍ. للتّعامل مع مثل هذا الكمّ من البيانات، يتوجّب على عالم البيانات المعرفة بكيفيّة التّعامل مع هذا الكمّ من البيانات، وكيفيّة تخزينها، والأدوات الّتي يمكنه استخدامها لتسهيل هذا الأمر مثل: برنامج هادوب. يمتلك هادوب نظام تخزينٍ موزّعٍ يستخدم نموذجًا يُدعى: ماب ريديوس (MapReduce)، ويحتوي على العديد من المكتبات مثل: أباتشي بيج (Apache Pig)، وهايف (بالإنجليزيّة: Hive)، وإتش بيز (HBase). تساعد كلّ هذه الأدوات في التّعامل مع البيانات الضّخمة بشكلٍ سريعٍ وكفءٍ، ممّا يجعل برنامج هادوب أحد أكثر البرامج شعبيّةً للتّعامل مع البيانات الضّخمة.
برنامج تابلو (Tableau)
برنامج تابلو هو أحد البرامج المتخصّصة في إظهار البيانات في صورةٍ رسوميّةٍ، وعمل الأشكال والرّسومات البيانيّة، ممّا يمكّن المستخدم من عمل رسوماتٍ تفاعليّةٍ ولوحاتٍ رسوميّةٍ (Dashboards)، تساعد في إظهار البيانات في صورةٍ أكثر أناقةً. تساعد هذه الخصائص في جعل برنامج تابلو اختيارًا مثاليًّا لإظهار التّوجّهات المختلفة والرّؤى من البيانات في صورة مخطّطاتٍ تفاعليّةٍ مثل: المخطّطات شجريّة الهيكليّة (Treemaps)، والمدرّجات التّكراريّة (Histograms)، والمخطّطات الصّندوقيّة (Box Plots). إحدى ميزات برنامج تابلو الأخرى، هي القدرة على الاتّصال بالجداول البيانيّة، وقواعد البيانات المترابطة، والمنصّات السّحابيّة (Cloud Platform)، ممّا يسمح بالتّعامل مع البيانات بصورةٍ مباشرةٍ، وتسهيل الأمر على المستخدمين.
برنامج ويكا (Weka)
يعتبر برنامج ويكا أحد الخيارات المثاليّة للتّعامل مع مشكلات تعلّم الآلة. يُستخدم ويكا في الأساس في عمليّات التّنقيب عن البيانات، ولكنّه يحتوي أيضًا على العديد من الأدوات المستخدمة في عمل نماذج تعلّم الآلة. يعتبر ويكا برنامجًا مفتوح المصدر، وهو يستخدم واجهة مستخدمٍ رسوميّةٍ (GUI)؛ ممّا يجعل التّعامل مع البرنامج أكثر سهولةً للمستخدمين، ودون الحاجة لكتابة سطرٍ برمجيٍّ واحدٍ.
تطبيقات علم البيانات
أصبح علم البيانات واحدًا من العلوم المهمّة والّتي لا غنًى عنها في كثيرٍ من القطاعات، مثل: الطّبّ، والخدمات البنكيّة، والصّناعات، وخدمات النّقل، إلخ. نستعرض في الأسطر القادمة بعض تطبيقات هذا العلم الشيّق.[2]
علم البيانات في مجال الرعاية الصحية
يلعب علم البيانات دورًا هامًا وحيويًّا في مجال الرّعاية الصّحيّة. يمكن للأطبّاء الكشف عن السّرطان أو الأورام الأخرى في مراحل مبكّرةٍ باستخدام خوارزميّات التّصنيف، وبرامج التّعرّف على الصّور والأنماط (Image Recognition)، كما تستخدم الصّناعات الوراثيّة علم البيانات أيضًا لتحليل وتصنيف أنماط التّسلسل الجينيّ. وتوجد العديد من الأجهزة المساعدة الافتراضيّة (Virtual Assistant) الّتي تساعد المرضى على التّغلّب على مشاكلهم الصّحيّة والعقليّة.[2]
علم البيانات في مجال التجارة الإلكترونية
تستخدم مواقع مثل أمازون نظام توصياتٍ يقوم بترشيح العديد من المنتجات للعملاء بناءً على بيانات الشّراء السّابقة لهم. يطوّر علماء البيانات أنظمة التّوصيات هذه للتّنبّؤ بتفضيلات العملاء باستخدام تقنيّات تعلّم الآلة.[2]
علم البيانات في مجال التصنيع
أصبح للأجهزة الآليّة والرّوبوتات دورٌ كبيرٌ في مجالات الصّناعة المختلفة، لقيامها بوظائف معتادةٍ وتكراريّةٍ بكفاءةٍ كبيرةٍ. يعتمد مبدأ عمل هذه الرّوبوتات على مبدأ الاستقلاليّة أو الحكم الذّاتيّ باستخدام تقنيّات علم البيانات مثل: التعلّم المعزّز، والتّعرّف على الصّور.[2]
علم البيانات في أنظمة التحدث الآلي
تستخدم أنظمة التّحدّث الآليّ مثل: ألِكسا الخاصّة بأمازن، وسيري الخاصّة بشركة أبل أنظمة التّعرّف على الكلام (Speech Recognition) لفهم المستخدمين. يقوم علماء البيانات بتطوير نظام التّعرّف على الكلام لتحويل كلام البشر لبياناتٍ كتابيّةٍ يمكن للآلة فهمها، بالإضافة لاستخدام عدّة خوارزميّاتٍ لتعلّم الآلة؛ لتصنيف أسئلة المستخدمين، وتوفير أنسب استجابةٍ ممكنةٍ.[2]
علم البيانات في مجال النقل
تستخدم السّيّارات ذاتيّة القيادة مبدأ الحكم الذّاتيّ والّذي يعتمد على تقنيّات التّعلّم المعزّز، وخوارزميّات الاكتشاف (Detection Algorithms)، والّتي جعلت من السّيّارات ذاتيّة القيادة أمرًا لم يعد بالخيال العلميّ، وكلّ ذلك بفضل التّقدّم في علم البيانات.[2]
علم البيانات والمستقبل
كلّما ازداد انتشار أجهزة الكمبيوتر حول العالم، ازداد كمّ البيانات الّتي نتعامل معها في واقعنا المعاصر. يعتبر علم البيانات أحد السّبل الرّئيسيّة لنتمكّن من التّعامل مع هذا الكمّ من البيانات، وأحد أهمّ العلوم وأكثرها متعةً لهؤلاء الّذين يحبّون التّجربة وحلّ المشكلات. فإذا كنت من هذا النّوع من البشر الّذي يريد أن يعرف كيف تعمل الأشياء من حولنا، فليس من سبيلٍ أفضل من الولوج من باب علم البيانات، أكثر مجالات العلم متعةً في عصرنا الحاليّ.[1][2]
| الدور | الاسم |
|---|---|
| إعداد | محمود صلاح نافع |

2 Responses
أنا اشكركم عظيم الشكر على ما تقدمونه للمحتوى العلمي